Layers
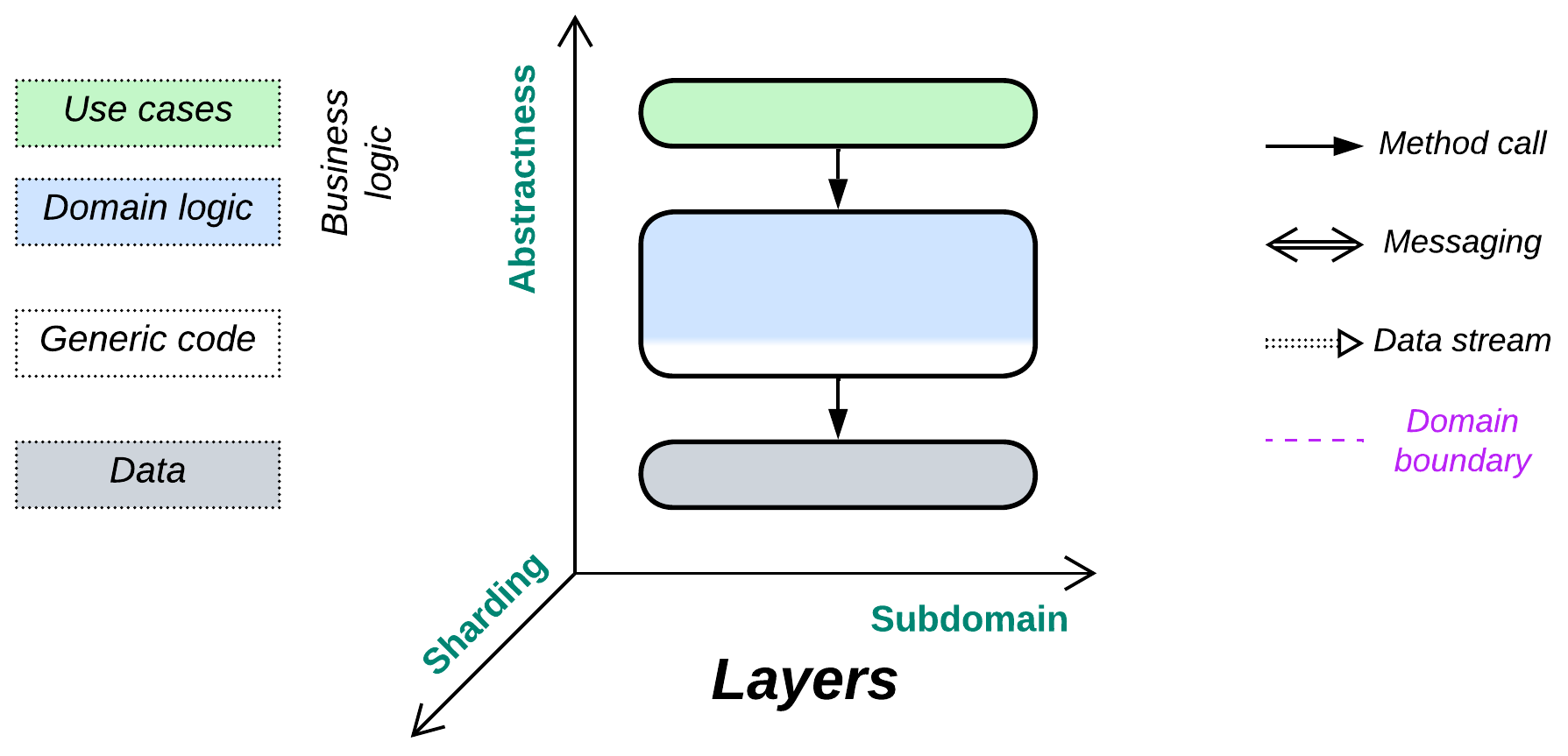
Yet another layer of indirection. Don’t mix the business logic and implementation details.
Known as: Layers [POSA1, POSA4], Layered Architecture [SAP, FSA, LDDD], Multitier Architecture, and N-tier Architecture [LDDD].
Variants: Open or closed, the number of layers.
By isolation:
- Synchronous layers / Layered Monolith [FSA],
- Asynchronous layers,
- A process per layer,
- Distributed tiers.
Layer roles:
- Interface (API or UI),
- Application (use cases or integration),
- Domain (business rules or model),
- Generic code (libraries and utilities),
- Communication (middleware),
- Data (persistence),
- Operating system and hardware.
Examples:
- Entity-Control-Boundary (ECB) / Entity-Boundary-Control (EBC) / Boundary-Control-Entity (BCE),
- Domain-Driven Design (DDD) Layers [DDD],
- Three-Tier Architecture,
- Embedded Systems.
Structure: A component per level of abstractness.
Type: Main, implementation.
| Benefits | Drawbacks |
|---|---|
| Rapid start for development | Quickly deteriorates as the project grows |
| Easy debugging | Hard to develop with more than a few teams |
| Good performance | Does not solve force conflicts between subdomains |
| Development teams may specialize | Does not support aggressive optimizations |
| Business logic is encapsulated | |
| Allows resolution of conflicting forces | |
| Deployment to dedicated hardware | |
| Layers with no business logic are reusable |
References: [POSA1] and [FSA] discuss layered software in depth; [DDD] promotes the layered style; most of the architectures in Herberto Graça’s Software Architecture Chronicles are layered. The Wiki has a reasonably good article.
Layering a system creates interfaces between its levels of abstractness (high-level use cases, lower-level domain logic, infrastructure) while also retaining monolithic cohesiveness within each of the levels. That allows both for easy debugging inside each individual layer (no need to jump into another programming language or re-attach the debugger to a remote server) and enough flexibility to have a dedicated development team, tools, deployment, and scaling policies for each. Though layered code is slightly better than that of Monolith, thanks to the separation of concerns, one of the upper (business logic) layers may nonetheless grow too large for efficient development.
Splitting a system into layers tends to resolve conflicts of forces between its abstract and optimized parts: the top-level business logic changes rapidly and does not require much optimization (as its methods are called infrequently), thus it can be written in a high-level programming language. In contrast, infrastructure, which is called thousands of times per second, has stable workflows but must be thoroughly optimized and extremely well tested.
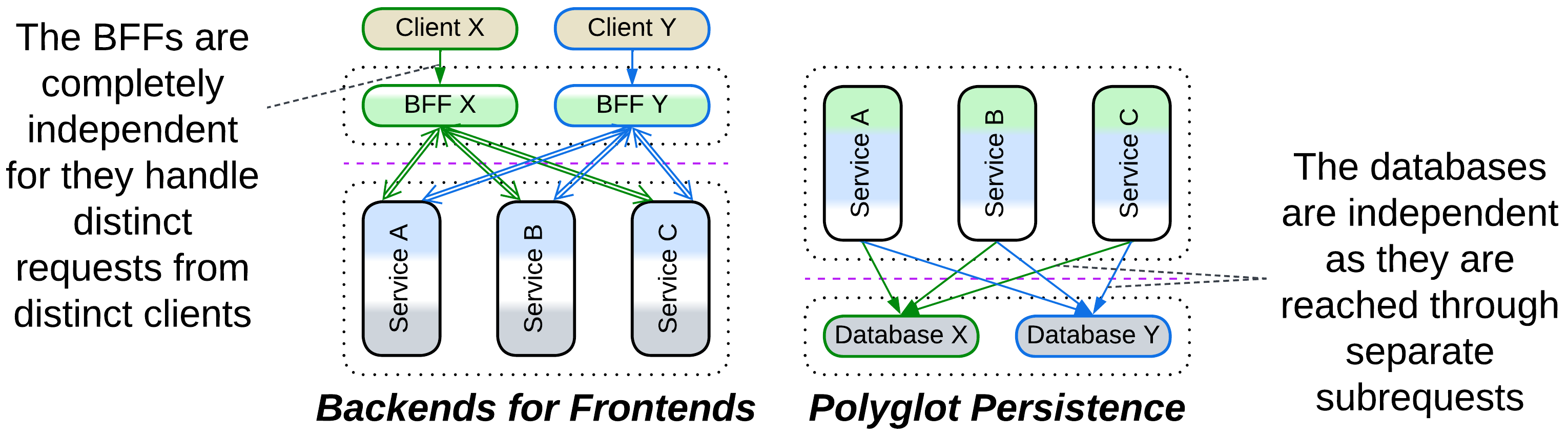
Many patterns have one or more of their layers split by subdomain, resulting in a layer of services. That causes no penalties as long as the services are completely independent (the original layer had zero coupling between its subdomains), which happens if each of them deals with a separate subset of requests (as in Backends for Frontends) or is choreographed by an upper layer (as in Polyglot Persistence, Hexagonal Architecture or Hierarchy) which boils down to the same “separate subset of subrequests” under the hood. However, if the services which form a layer need to intercommunicate, you immediately get a whole set of troubles with debugging, sharing data, and performance characteristic of the Services architecture.
Performance#
The performance of a layered system is shaped by two factors:
- Communication between layers is slower than within a layer. Components of a layer may access each other’s data directly, while accessing another layer involves data transformation (as interfaces tend to operate generic data structures), serialization, and often IPC or networking.
- The frequency and granularity of events or actions increases as we move from the upper more abstract layers to lower-level components that interface an OS or hardware.
There is a number of optimizations to skip interlayer calls:
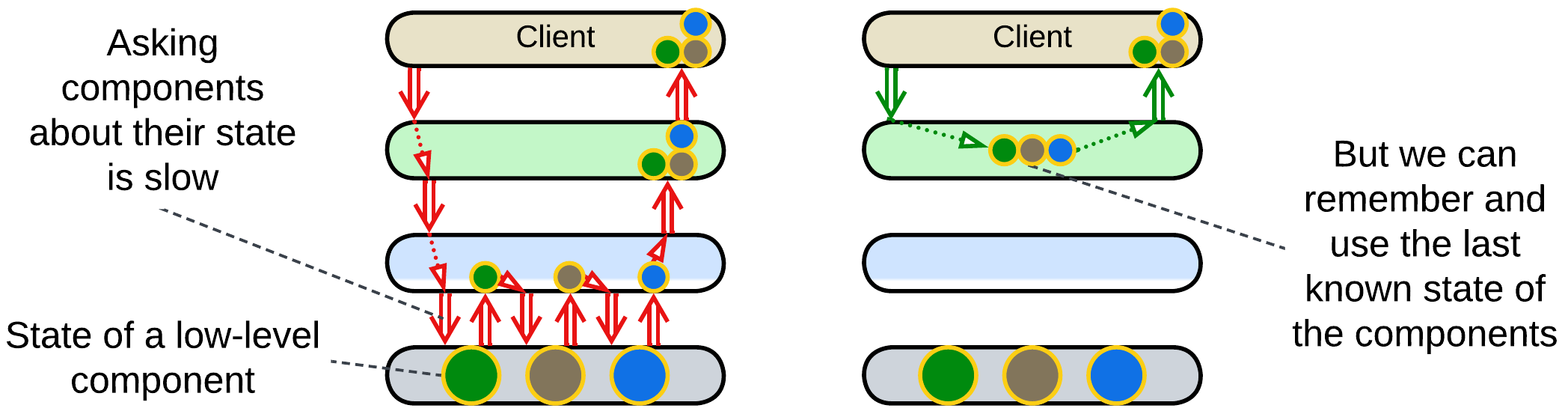
Caching: an upper layer tends to model (cache last known state of) the layers below it. This way it can behave as if it knew the state of the whole system without querying the actual state from the hardware below all the layers. Such an approach is universal for control software. For example, a network monitoring suite shows you the last known state of all the components it observes without actually querying them – it is subscribed to notifications and remembers what each device has previously reported.
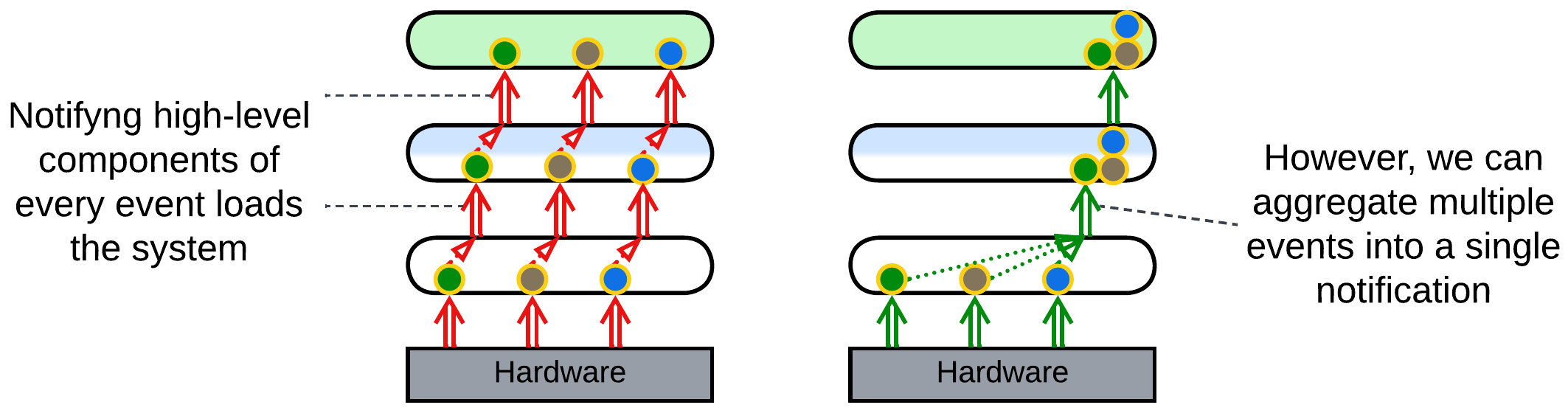
Aggregation: a lower layer collects multiple events before notifying the layer above it to avoid being overly chatty. An example is an IIoT field gateway that collects data from all the sensors in the building and sends it in a single report to the server. Or consider a data transfer over a network where a low-level driver collects multiple data packets that come from the hardware and sends an acknowledgement for each of them while waiting for a datagram or file transfer to complete. It notifies its client only once when all the data has been collected and its integrity confirmed.
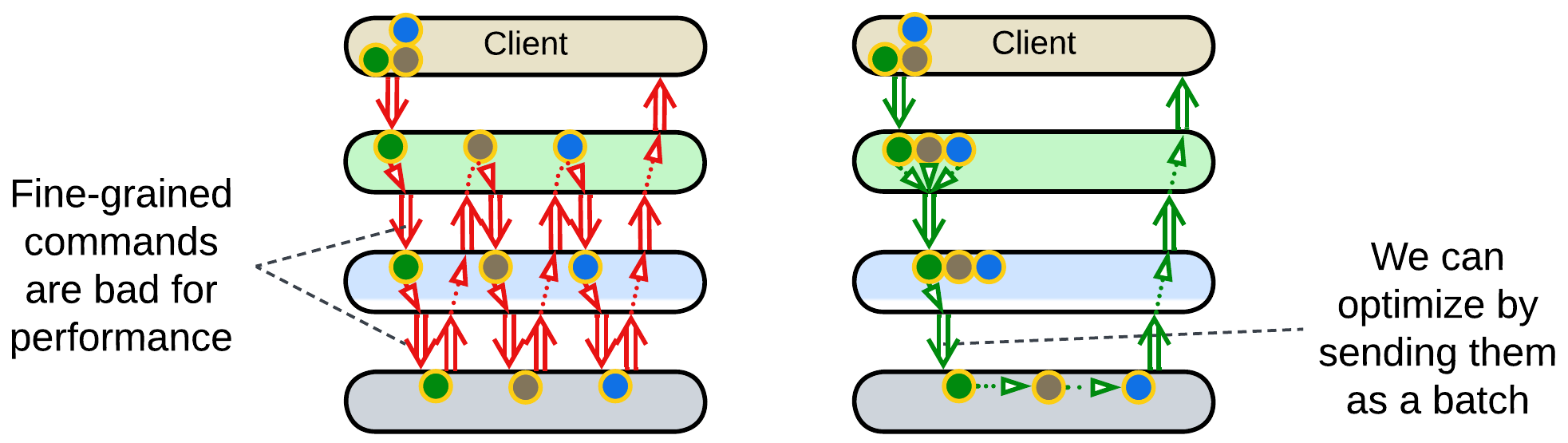
Batching: an upper layer forms a queue of commands and sends it as a single job to the layer below it. This takes place in drivers for complex low-level hardware, like printers, or in database access as stored procedures. [POSA4] describes the approach as Combined Method, Enumeration Method and Batch Method patterns. Programming languages and frameworks may implement foreach and map/reduce which allow for a single command to operate on multiple pieces of data.
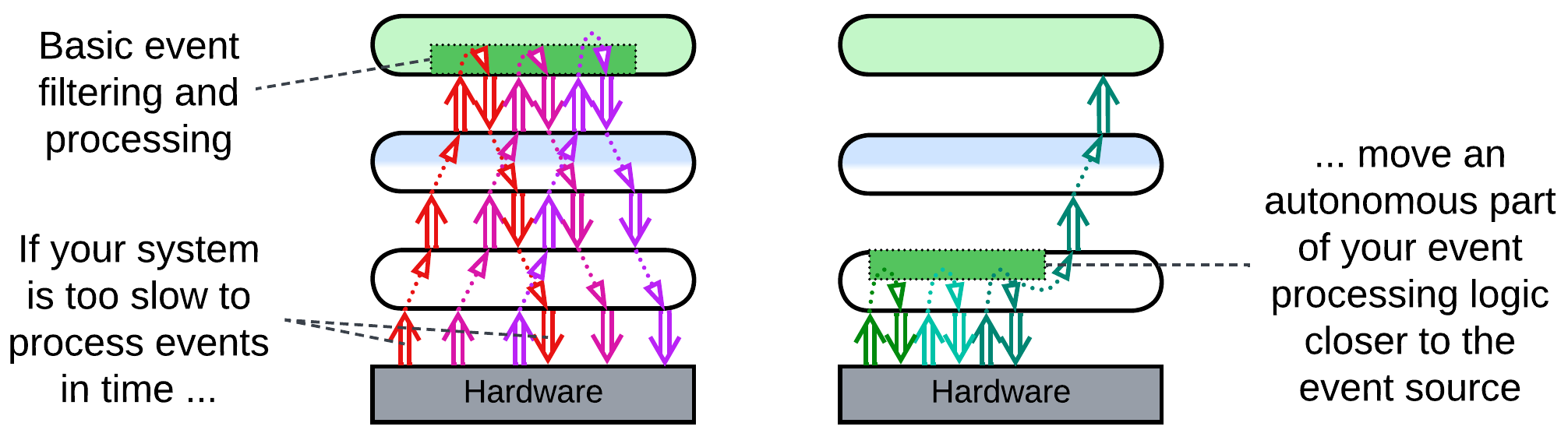
Strategy injection: an upper layer installs an event handler (hook) into the lower layer. The goal is for the hook to do basic pre-processing, filtering, aggregation, and decision making to process the majority of events autonomously while escalating to the upper layer in exceptional or important cases. That may help in such time-critical domains as high-frequency trading.
Layers can be scaled independently, as exemplified by common web applications that comprise a highly scalable and resource-consuming frontend, somewhat scalable backend and unscalable data layer. Another example is an OS (lower layer) that runs multiple user applications (upper layer).
Dependencies#
Usually an upper layer depends on the API (application programming interface) of the layer directly below it. That makes sense as the lower the layer is, the more stable it tends to be: a user-facing software gets updated on a daily or weekly basis while hardware drivers may not change for years. As every update of a component may destabilize other components that depend on it, it is much more preferable for a quickly evolving component to depend on others instead of the other way round.
Some domains, including embedded systems and telecom, require their lower layers to be polymorphic as they deal with varied hardware or communication protocols. In that case an upper layer (e.g. OS kernel) defines a service provider interface (SPI) which is implemented by every variant of the lower layer (e.g. a device driver). That allows for a single implementation of the upper layer to be interoperable with any subclass of the lower layer. Such an approach enables Plugins, Microkernel, and Hexagonal Architecture.
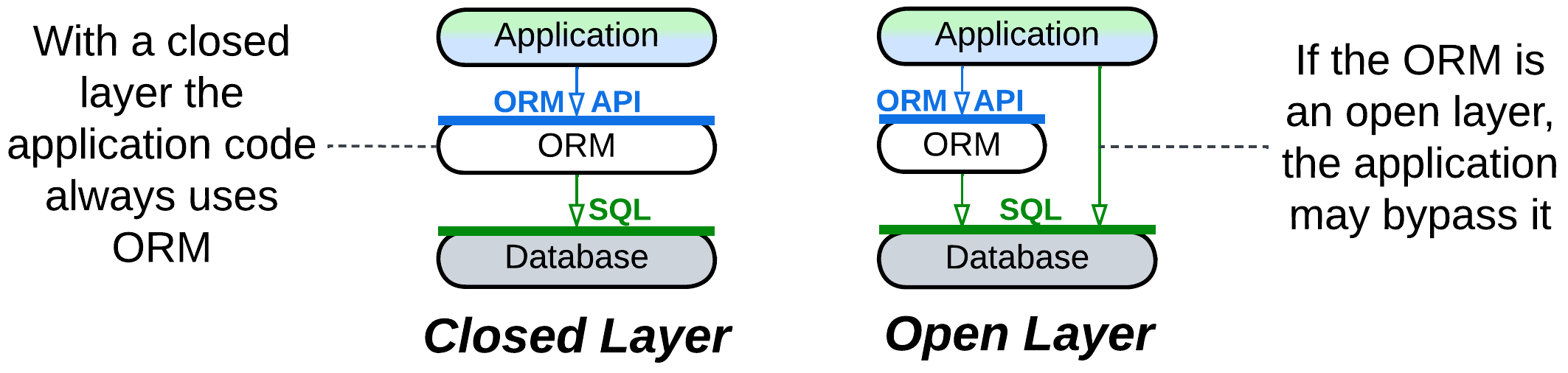
There may also be an Adapter layer between your system’s SPI and an external API. It is called Anticorruption Layer [DDD], Database Abstraction Layer / Database Access Layer [POSA4] / Data Mapper [PEAA], OS Abstraction Layer or Platform Abstraction Layer / Hardware Abstraction Layer, depending on what kind of component it adapts.
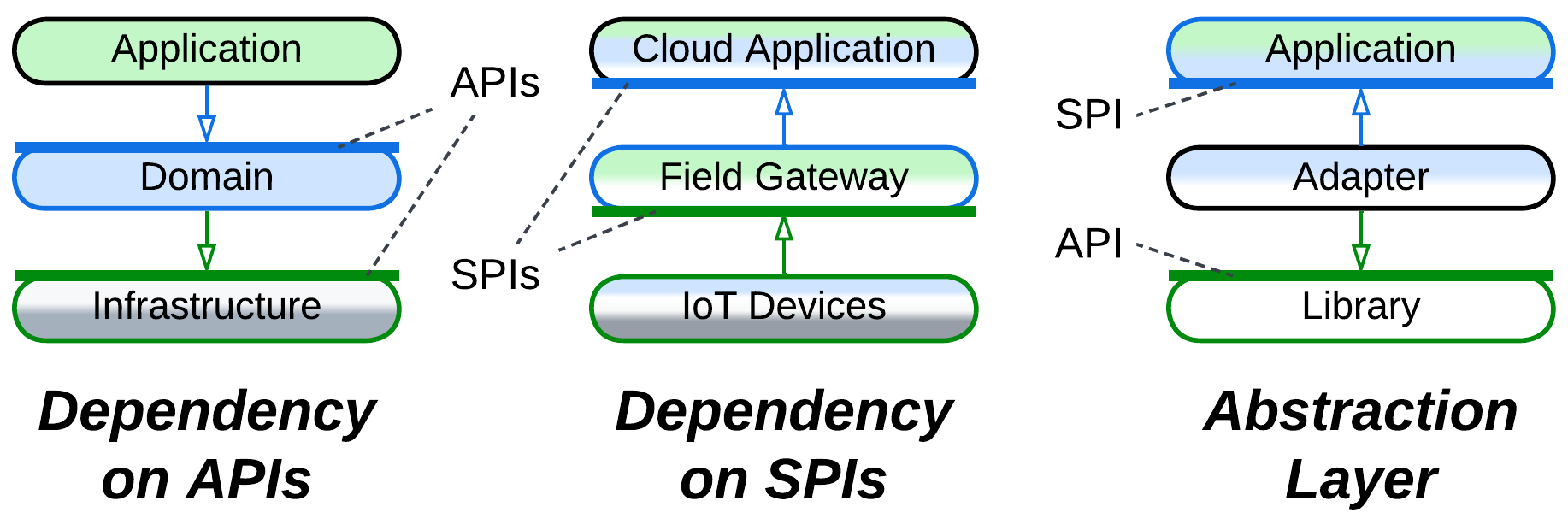
A layer can be closed (strict) or open (relaxed). A layer above a closed layer depends only on the closed layer right below it – it does not see through it. Conversely, a layer above an open layer depends on both the open layer and the layer below it. The open layer is transparent. That helps keep a layer which encapsulates one or two subdomains small: if such a layer were closed, it would have to copy much of the interface of the layer below it just to pass the incoming requests which it does not handle through to the layer below. The optimization of the open layer has a cost: the team that works on the layer above an open layer needs to learn two APIs which may have incompatible terminology.
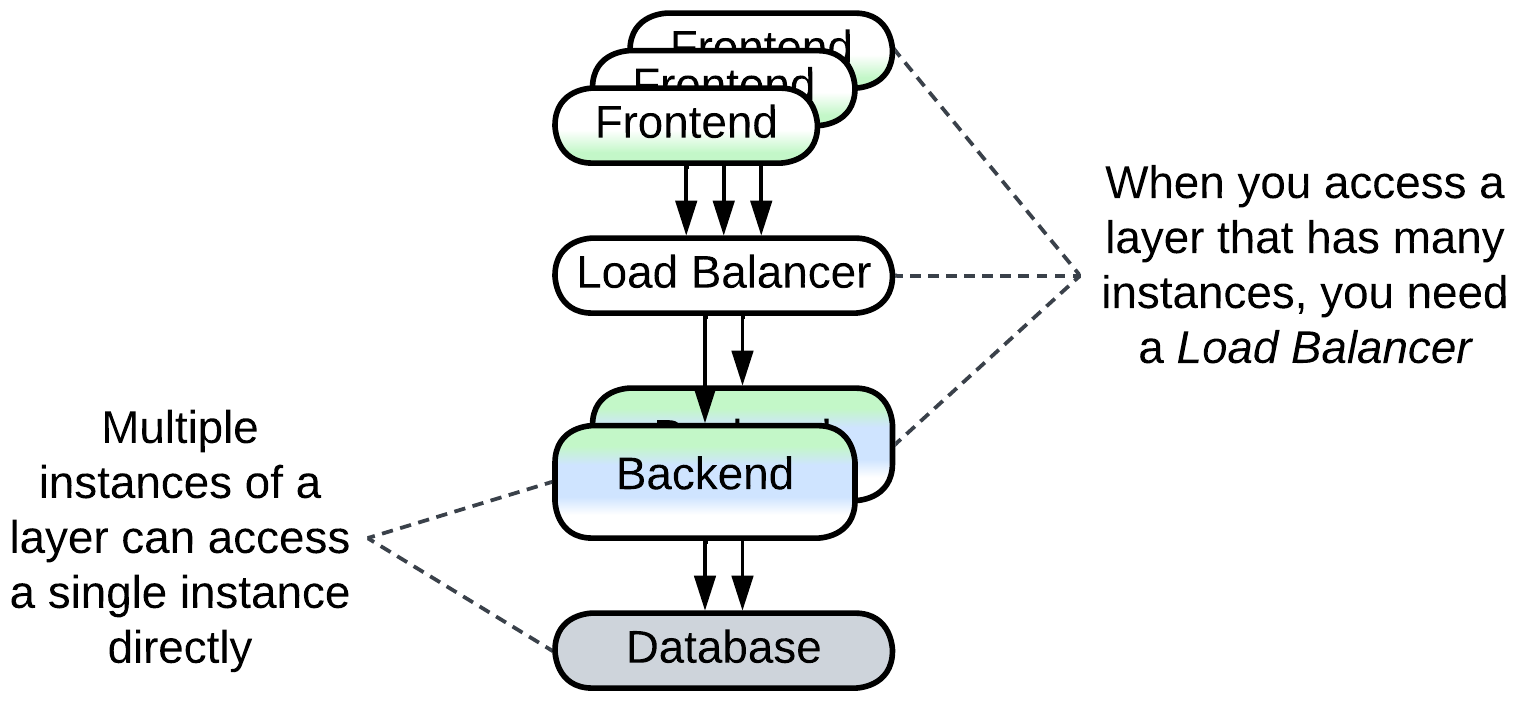
If you ever need to scale (run multiple instances of) a layer, you may notice that a layer which sends requests naturally supports multiple instances, with the instance address being appended to each request so that its destination layer knows where to send the response. On the other hand, if there are multiple instances of a layer you call into, you need a kind of Load Balancer to dispatch requests among the instances.
Applicability#
Layers are good for:
- Small and medium-sized projects. Separating the business logic from the low-level code should be enough to work comfortably on codebases below 100 000 lines in size.
- Specialized teams. You can have a team per layer: some people, who are proficient in optimization, work on the highly loaded infrastructure, while others talk to the customers and write the business logic.
- Deployment to a specific hardware. Frontend instances run on client devices, a backend needs much RAM, the data layer demands a large HDD and security. There is no way to unite them into a single generic component.
- Flexible scaling. It is common to have hundreds or thousands of frontend instances being served by several backend processes that use a single database.
- Real-time systems. Hardware components and network events often need the software to respond within a set time limit. This is achievable by separating the time-critical code from normal priority calculations. See Hexagonal Architecture and Microkernel for improved solutions.
Layers are bad for:
- Large projects. You are still going to enter monolithic hell [MP] if you reach 1 000 000 lines of code.
- Low-latency decision making. If your business logic needs to be applied in real time, you cannot tolerate the extra latency caused by the interlayer communication.
Relations#
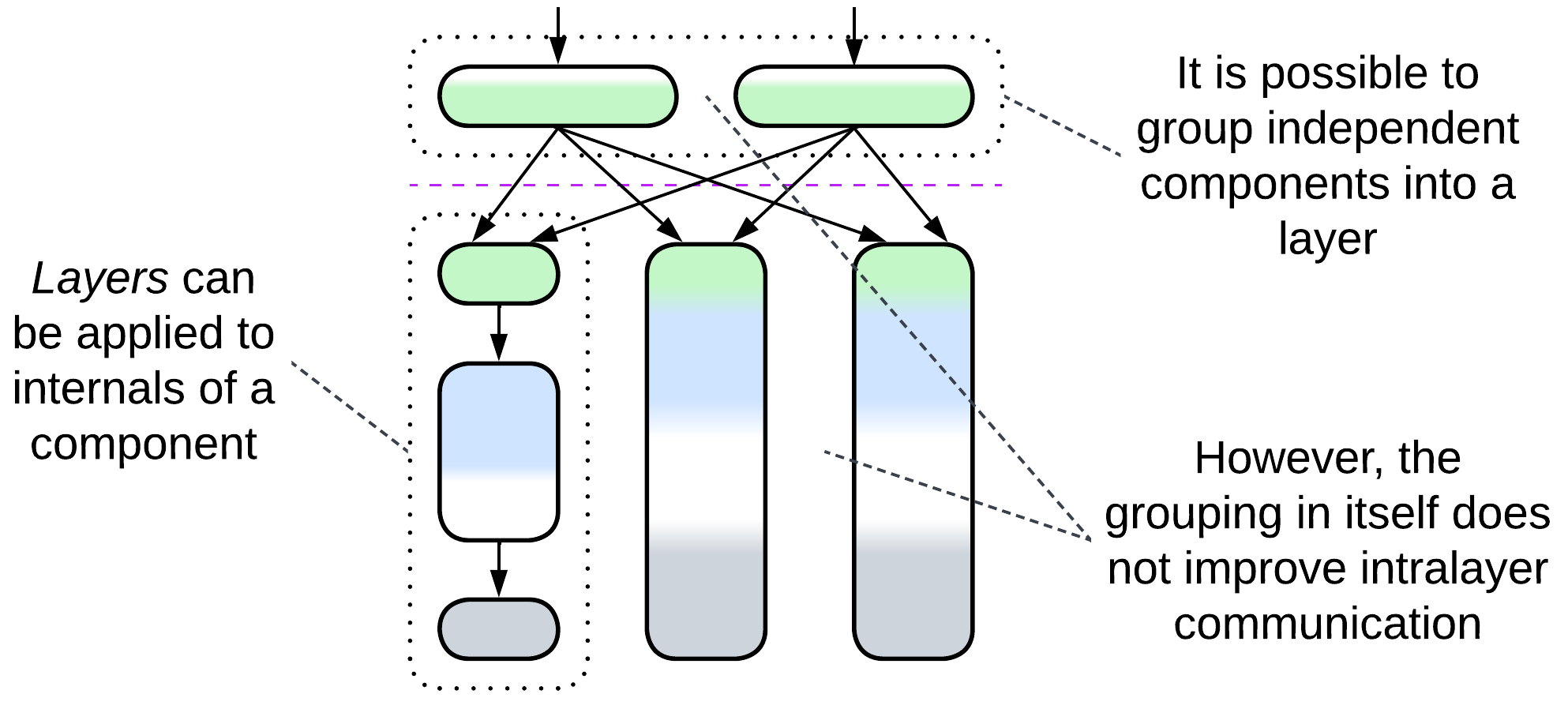
Layers:
- Can be applied to the internals of any module, for example, layering Services results in Layered Services.
- Can be altered by Plugins or extended with a Proxy, Orchestrator, and/or Shared Repository to form an extra layer.
- Can be implemented by Services yielding layers of services present in Service-Oriented Architecture, Backends for Frontends, or Polyglot Persistence.
- May be closely related to Hexagonal Architecture or the derived Separated Presentation.
- A layer often serves as a Proxy, Orchestrator, and/or (Shared) Repository.
Variants by isolation#
There are several grades of layer isolation between unstructured Monolith and distributed Tiers. All of them are widely used in practice: each step adds its specific benefits and drawbacks to those of the previous stages until at some point it makes more sense to reject the next deal because its cons are too inconvenient for you.
Synchronous layers, Layered Monolith#
First you separate the high-level logic from low-level implementation details. Then draw interfaces between them. The layers will still call each other directly, but at least the code has been sorted out into some kind of structure, and you can now employ two or three dedicated teams, one per layer. The cost is quite low – it is that the newly created interfaces will stand in the way of aggressive performance optimization.
| Benefits | Drawbacks |
|---|---|
| Structured code | Lost opportunities for optimization |
| Two or three teams |
Asynchronous layers#
For the next step you may decide to take will be to isolate the layers’ execution threads and data. The layers will communicate only through in-process messages, which are slower than direct calls and harder to debug, but now each layer can run at its own pace – a must for interactive systems.
| Benefits | Drawbacks |
|---|---|
| Structured code | No opportunities for optimization |
| Two or three teams | Some troubles with debugging |
| The layers may differ in latency |
A process per layer#
Next, you may run each layer in a separate process. You have to devise an efficient means of communication between them, but now the layers may differ in technologies, security, frequency of deployment, and even stability – the crash of one layer does not impact any of the others. Moreover, you may scale each layer to make good use of the available CPU cores. However, you will pay through even harder debugging, lower performance, and you will have to take care of error recovery, because if one of the components crashes, the others are likely to remain in an inconsistent state.
| Benefits | Drawbacks |
|---|---|
| Structured code | No opportunities for optimization |
| Two or three teams | Troublesome debugging |
| The layers may differ in latency | Some performance penalty |
| The layers may differ in technologies | Error recovery must be addressed |
| The layers are deployed independently | |
| Software security isolation | |
| Software fault isolation | |
| Limited scalability |
Distributed tiers#
Finally, you may separate the hardware which the processes run on – going all out for distribution. This allows you to fine-tune the system configuration, run parts of the system close to its clients, and physically isolate the most secure components, with your scalability limited only by your budget. The price is paid in latency and debugging experience.
| Benefits | Drawbacks |
|---|---|
| Structured code | No opportunities for optimization |
| Two or three teams | Even worse debugging |
| The layers may differ in latency | Definite performance penalty |
| The layers may differ in technologies | Error recovery must be addressed |
| The layers are deployed independently | |
| Full security isolation | |
| Full fault isolation | |
| Full scalability | |
| Layers vary in hardware setup | |
| Deployment close to clients |
Variants of layer roles#
Though the structure of every software system is unique, there is a common set of roles or functions that need to be covered by its code. It is common wisdom that a piece of code should do one thing, and do it well, thus the code written to support the same kind of functionality tends to stick together and end up in a dedicated layer of a system. This also helps your teams specialize and keeps their cognitive load low by limiting the amount of code they deal with, which allows for high productivity.
That clarity of design, which separates technically different pieces, is opposed by a host of more pragmatic forces that compel you to keep your code together:
- Performance can be easily optimized inside a component, while any communication between components will likely be much slower.
- If many distinct workflows traverse a set of components, those components require large interfaces which take much effort to design, implement, and support. You may end up spending more time maintaining your perfect architecture than writing the business logic which earns money for the company.
- The more components you have, the harder it is to deploy them and keep them consistent, not to mention error recovery. Moreover, as the number of system components increases, the big picture becomes elusive, and soon there is nobody who knows how to change the system if need arises.
Balancing the cohesers and decouplers listed above results in coarse-grained system components each of which covers several concerns, with some real-world system compositions shown in the Examples section later in this chapter. However, first we need to see which kinds of roles a system layer may incorporate:

Interface (API or UI)#
If a system serves a human user or remote client software, there is a part of it, called an interface, that deals with communication and translation between the system’s internal data model and one convenient for its clients.
As an interface represents the system to its clients, it is a kind of Proxy by definition [GoF]. If the client is another software system, the interface is called Application Programming Interface (API) and is likely to be implemented by a Gateway which will receive a message through a well-known protocol, check its correctness and authenticity of the sender, and forward the message’s payload to a layer below it. In most cases it will also send response and notification messages by executing the converse tasks: translation from the system’s internal data format to something more convenient for its clients and sending the resulting message over a network protocol.
When a system interacts with a human, it exposes another kind of interface – Human-Machine Interface (HMI) or User Interface (UI). The basics of its action are similar to the case of software-to-software interaction described above save that humans prefer visual or textual information instead of a highly structured Internet protocol.
Another, less common kind of interface is called Service Provider Interface (SPI). It is declared by a system that relies on an external component and is implemented by that component’s authors to make it pluggable into the system. SPIs are in use by Plugins and Microkernel topologies, with device drivers being the best known example of pluggable components.
Other kinds of Proxies adapt a system to foreign interfaces:
- An Anticorruption Layer or Open Host Service translates between two software subsystems to loosen dependencies between them.
- A Hardware Abstraction Layer or Operating System Abstraction Layer stands between a system and an underlying hardware or OS, respectively, to make the system portable.

A Proxy that implements an interface may reside in a dedicated layer (and there may be multiple Proxies stacked together, for example, a Gateway behind a Firewall) or be merged with a neighboring layer: for example, an API Gateway fills the roles of both interface and application.
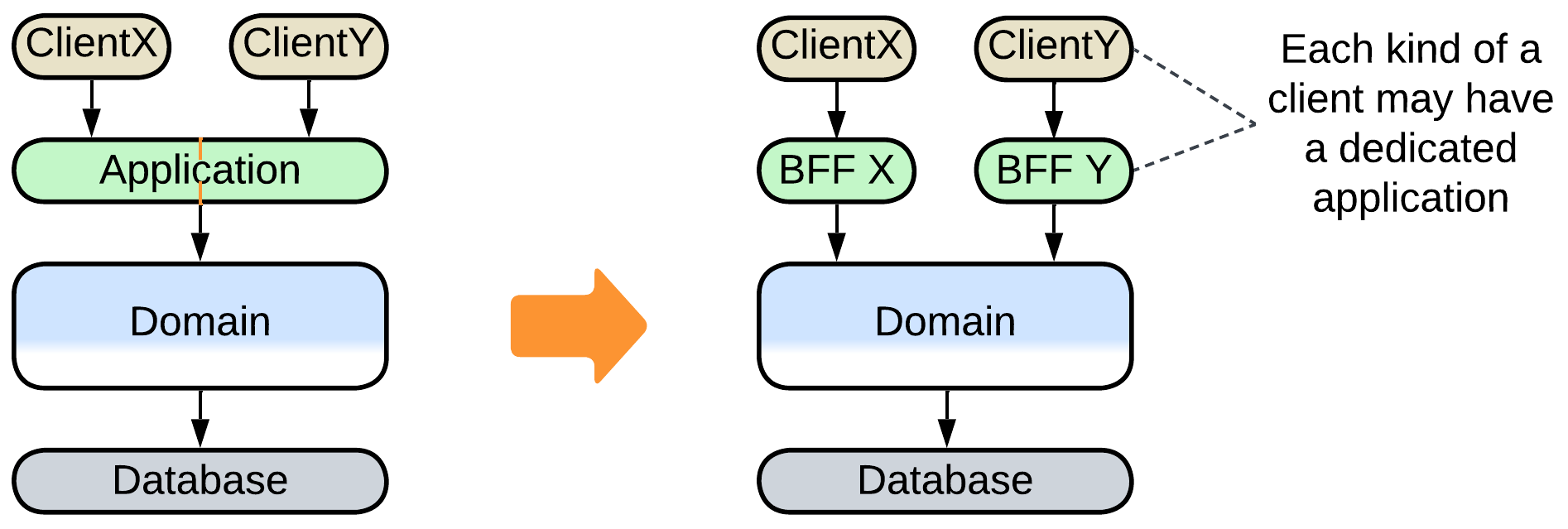
An interface layer can contain multiple components (services, modules, or high-level classes) when the system below it supports several kinds of clients: a bank is likely to provide a web interface, a mobile application, and a SWIFT endpoint. See Backends for Frontends for a detailed description.

Application (use cases or integration)#
The application is what your system does. If it faces clients, the application runs client commands, called use cases, by executing chains of calls to its model which knows how to do simple actions – the building blocks from which a use case consists.
For example, to transfer money between accounts, the application asks the model to:
- Verify that the client is the owner of the account to be charged.
- Calculate the bank’s fee for the transfer.
- Subtract the amount to be transferred and the fee from the client’s account.
- Add the fee to the bank’s account.
- Tell the recipient’s bank to add the transferred amount to the target account.
It is also responsible for dealing with any error that may occur in the process. For example, if the target account does not exist or is blocked, the application will need to both refund the client and return a meaningful error message in the client’s preferred language.
Another form of application, called control systems, is written to supervise hardware or software entities. In that case there are no client requests or use cases – instead, the system reacts to signals from the components controlled. It is the application layer which is responsible for the system’s behavior: if a smoke sensor detects fire, the application tells an alarm to sound. This role is called integration – the system acts as a living organism, all its parts orderly moving in response to a stimulus perceived by a sense.
When an application resides in a dedicated layer, it is called an Orchestrator. Like the interface layer, the application layer may also contain multiple components: the bank will likely have distinct applications for its clients and for its managers. The corresponding pattern is also called Backends for Frontends (there is little distinction between Proxies and Orchestrators in that topology).
Some systems lack the application role – they are structured as Pipelines, so that whatever enters one end of the system passes through all its components and pops out, digested, at the end. In that case it is the very structure of the system – the connections between its components – that drive the order of events.

Domain (business rules or model)#
The domain layer models the real-world system which your software operates or emulates. It contains rules that describe how to do anything that your clients may want or how the hardware which you control is expected to operate.
Back to the banking example, the domain layer can:
- Find if an account is valid and who owns it.
- Calculate a fee.
- Add money to or subtract it from an account.
- Transfer money to another bank.
And it has some tricks up its sleeves to assure that nothing it does about money is ever lost, even if the network is disconnected or the hardware it runs on fails.
In most cases the domain layer is the largest one and it is the one which makes your software valuable for business because it actually does whatever your software is about. It is also the only layer in which OOP classes may model real-world entities.
As the largest layer, the domain is the first among them to be subdivided:
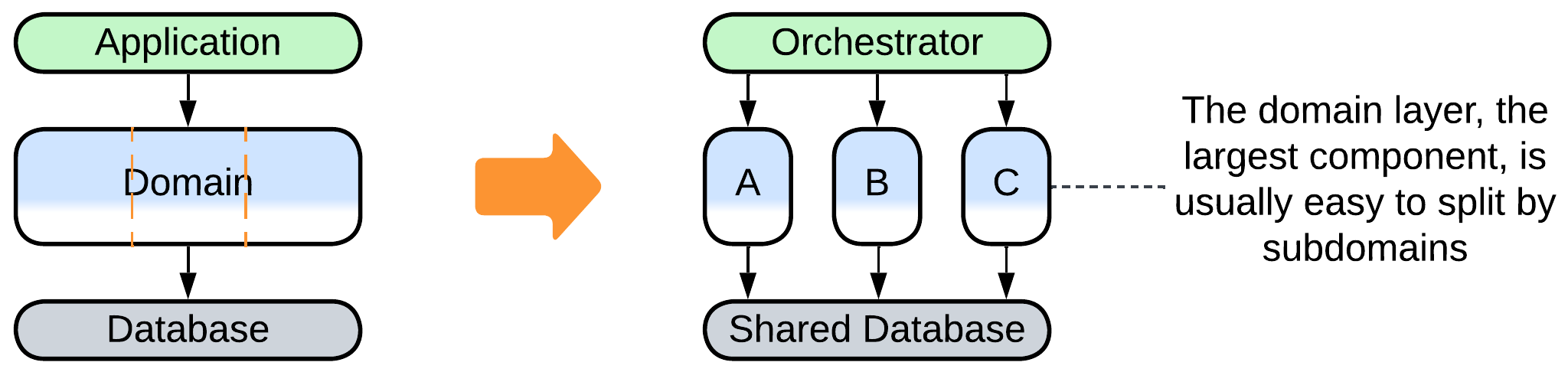
- The most common way is to partition it into subdomains – loosely coupled subsets of your system’s functionality – yielding Services (when other layers are fragmented along the same lines or replicated among the subdomain components) or a derived architecture with several layers remaining intact.
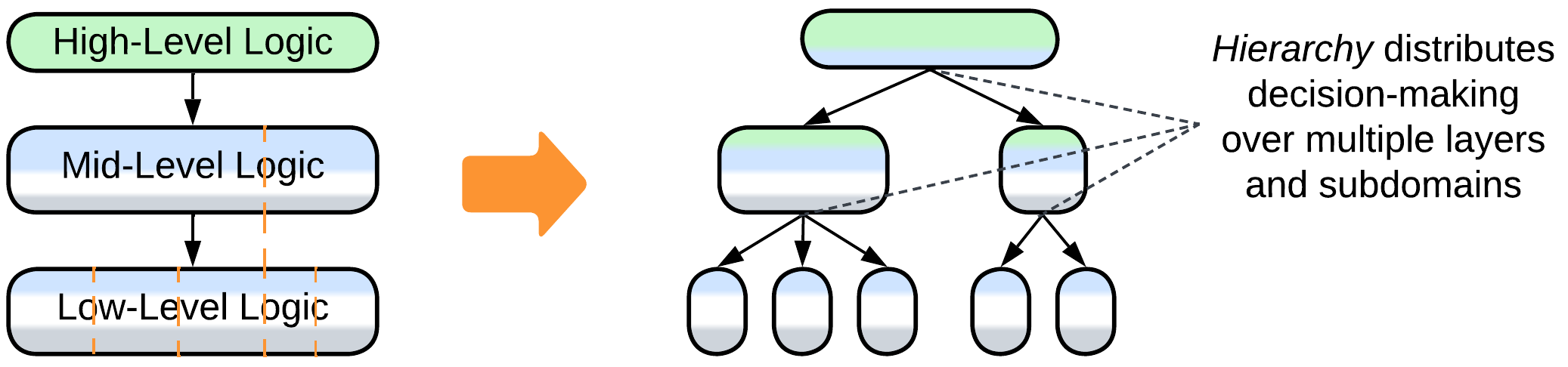
- Rare cases allow for hierarchical decomposition where most components blend application and domain roles.
- Last but not least, we can use separate models for making changes (executing commands) and for analytics (running queries), giving rise to Command Query Responsibility Segregation (CQRS). This makes sense because a command usually involves many fields of a single record (database row) while a query runs over select rows of all the records – they vary in how they access and treat the data. It is common to have a record wrapped into an OOP class in the command model, while the query model, if it is not omitted completely, provides for direct access to the database.

Generic code (libraries and utilities)#
Generic code is something unrelated to your business but still used by your logic: a graph traversal algorithm, an e-mail server, or even a computer vision framework to identify duplicate user avatars.
In most cases generic code stays together with the domain-level code which calls it. However, when the domain layer gets subdivided into services, there emerge multiple options:
- If the generic code is not shared, it moves into the service that uses it. See Services.
- If it needs to be shared, it can be:
- Extracted into a dedicated service, as in Service-Oriented Architecture.
- Replicated as a Sidecar attached to every instance of each service that uses it.
- Copied into the codebases of the services to allow each team to change it independently from other teams – see Separate Ways in [DDD].

Communication (middleware)#
If your system is comprised of multiple components, they need a way to communicate, which may be as simple as in-process method calls or as complex as a distributed consensus protocol. The communication infrastructure, when used consistently throughout a system, makes a distinct virtual (conjoining separately deployed nodes) system layer, called Middleware.

Data (persistence)#
Most systems but the simplest Pipelines are stateful – they remember something about their users or their environment:
- A backend would usually persist useful facts to a database which makes a dedicated persistence layer.
- A real-time control system does not have the leisure to access anything remote, therefore its state is embedded in-memory into its domain layer.
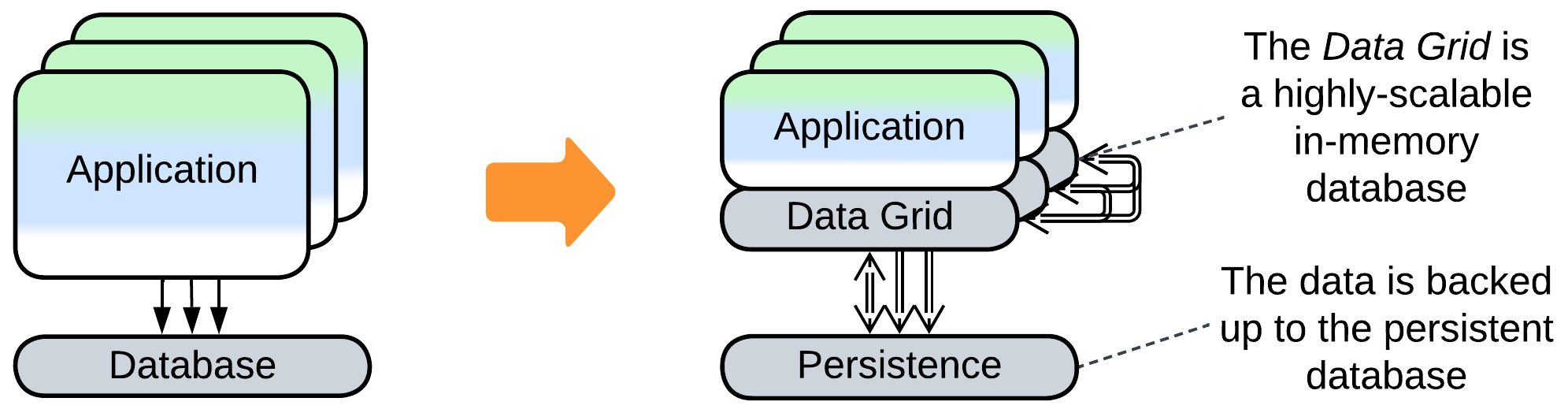
- Complex distributed frameworks that implement Actors or Space-Based Architecture both keep each service’s data inside the service’s memory for fast access and back all the changes to a persistent datastore to support failure recovery.

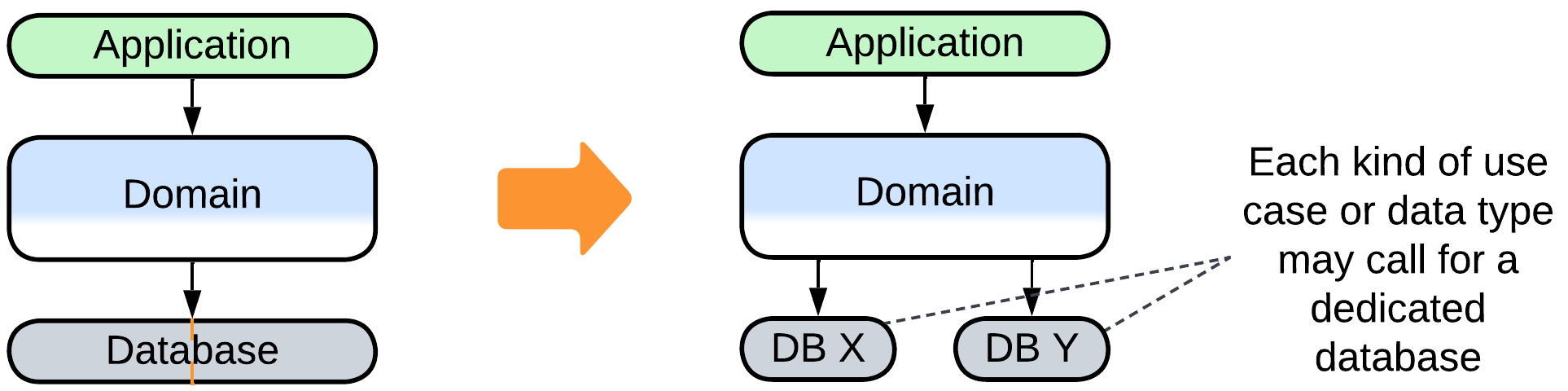
If the persistence layer becomes a system’s performance bottleneck, as it often does, one of the cures is using several specialized datastores, leading to Polyglot Persistence.

Operating system and hardware#
Your software always runs on hardware and usually relies on an operating system (OS) for file and network access and memory management. Even though many modern backends don’t care about such low-level details and omit them on their diagrams, embedded or system software communicates with its OS or hardware directly, making the corresponding components indispensable parts of its topology.
Integrating multiple pieces of hardware into an intelligently behaving system is usually what control software is written for. Such systems often follow Actors or Hierarchy architectures.
Examples#
The notion of layering seems to be so natural to our minds that most known architectures are layered. Not surprisingly, there are several approaches to assigning functionality to and naming the layers:
Entity-Control-Boundary (ECB), Entity-Boundary-Control (EBC), Boundary-Control-Entity (BCE)#

Entity-Control-Boundary (ECB) or other combinations of these words (EBC and BCE) designate a system composed of the following layers:
- Boundary – the layer which interacts with the system’s clients or users. See Proxy.
- Control – the layer which contains use cases – sequences of actions on the system’s internals that should be made to process a client’s request or respond to a user’s action. See Orchestrator.
- Entity – the bulk of the system’s business logic and data.
A closer look at an ECB system may reveal a finer-grained structure that resembles Backends for Frontends or Service-Oriented Architecture as each layer is composed of modules or objects:

Domain-Driven Design (DDD) Layers#
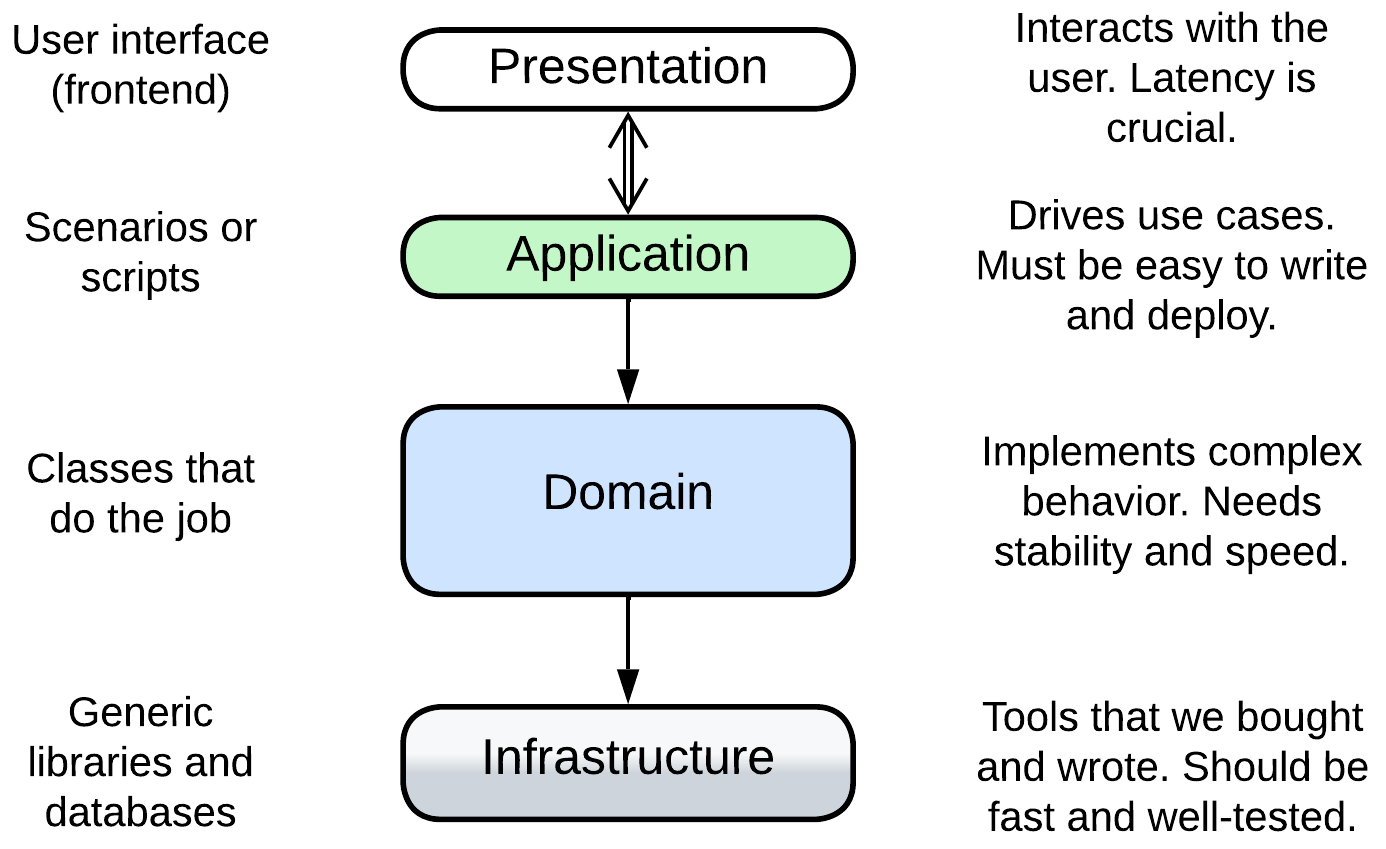
[DDD], a methodology for enterprise-scale backend development, extends the more generic Entity-Control-Boundary with a new Infrastructure layer responsible for communication and persistence roles which don’t exist in most desktop applications. Its layers are called:
- Presentation (User Interface) – the user-facing component (frontend, UI). It should be highly responsive to the user’s input. See Separated Presentation.
- Application (Integration, Service) – the high-level scenarios which build upon the API of the domain layer. It should be easy to change and to deploy. See Orchestrator.
- Domain (Model, Business Rules) – the bulk of the mid- and low-level business logic. It should usually be well-tested and performant.
- Infrastructure (Utility, Data Access) – the utility components devoid of business logic. Their stability and performance is business-critical but updates to their code are rare.
For example, an online banking system comprises:
- the presentation layer which is its frontend;
- the application layer which implements sequences of steps for payment, card to card transfer, and viewing a client’s history of transactions;
- the domain layer contains classes for various kinds of cards and accounts;
- the infrastructure layer with a database and libraries for encryption and interbank communication.
However in practice you are much more likely to encounter the derived DDD-style Hexagonal Architecture than the original DDD Layers.
Three-Tier Architecture#
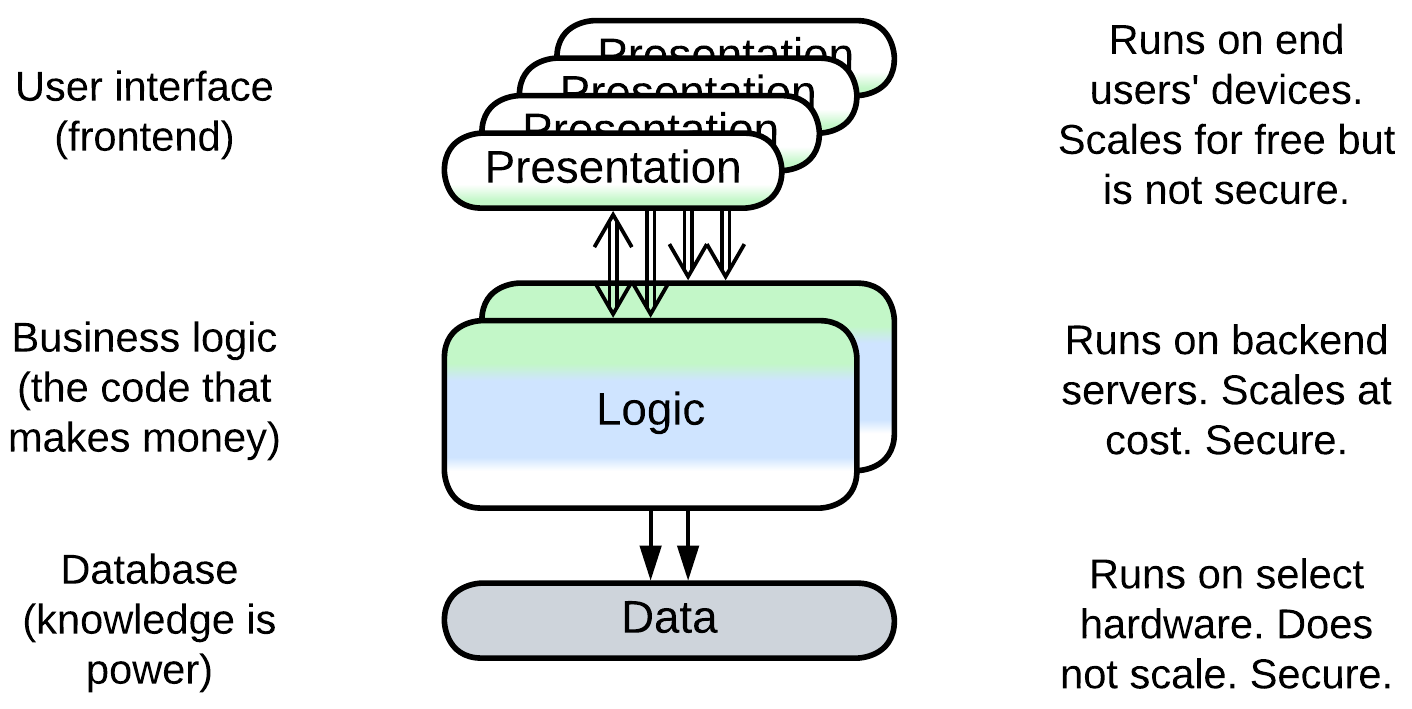
Here the focus lies with the distribution of the components over heterogeneous hardware (Tiers):
- Presentation (Frontend) tier – a user-facing application which runs on a user’s hardware. It is very scalable and responsive, but insecure.
- Logic (Backend) tier – the business logic which is deployed on the service provider’s side. Its scalability is limited mostly by the funding committed, security is good but latency is high.
- Data (Database) tier – a service provider’s database which runs on a dedicated server. It is not scalable but is very secure.
In this case the division into layers resolves the conflict between scalability, latency, security, and cost as discussed in detail in the chapter on distribution.
Embedded systems#
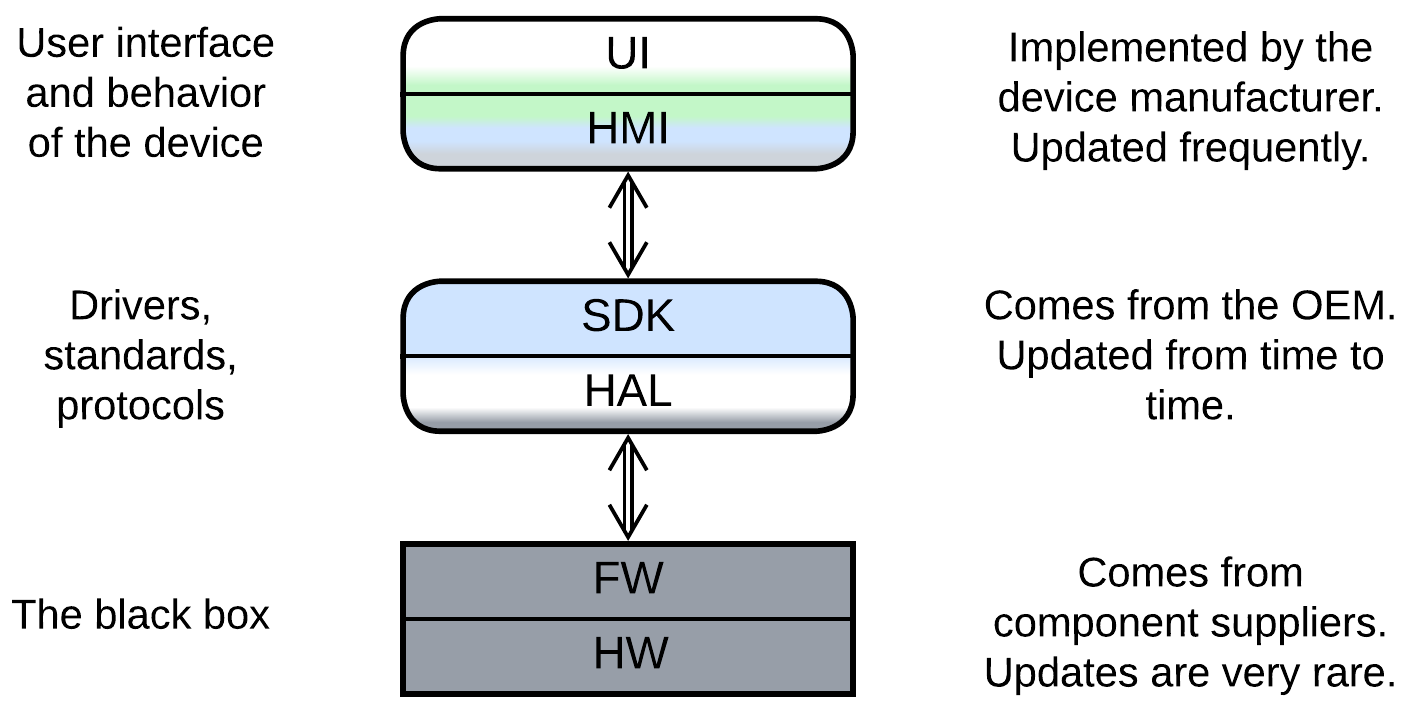
Bare metal and micro-OS systems which run on low-end chips use a different terminology, which is not unified across domains. A generic example involves:
- Presentation – a UI engine used by the HMI. It may be a third-party library or come as a part of the SDK.
- Human-Machine Interface (HMI aka MMI) – the UI and high-level business logic for user scenarios, written by a value-added reseller.
- Software Development Kit (SDK) – the mid-level business logic and device drivers, written by the original equipment manufacturer.
- Hardware Abstraction Layer (HAL) – the low-level code that abstracts hardware registers to enable code reuse between hardware platforms.
- Firmware of Hardware Components – usually closed-source binary pre-programmed into chips by chipmakers.
- Hardware itself.
It is of note that in this approach the layers form strongly coupled pairs. Each pair is implemented by a separate party of the supply chain, which is an extra force that shapes the system into layers.
An example of such a system can be found in an old mobile phone or a digital camera.
Evolutions#
Layers are not without drawbacks which may force your system to evolve. A summary of such evolutions is given below while more details can be found in Appendix E.
Evolutions that make more layers#
Not all the layered architectures are equally layered. A Monolith with a Proxy or database has already stepped into the realm of Layers but is far from reaping all its benefits. Such a system may continue its course in a few ways that were previously discussed for Monolith:
- Employing a database (if you don’t use one) lets you rely on a thoroughly optimized state-of-the-art subsystem for data processing and storage.
- Proxies are similarly reusable generic modules to be added at will.
- Implementing an Orchestrator on top of your system may improve programming experience and runtime performance for your clients.
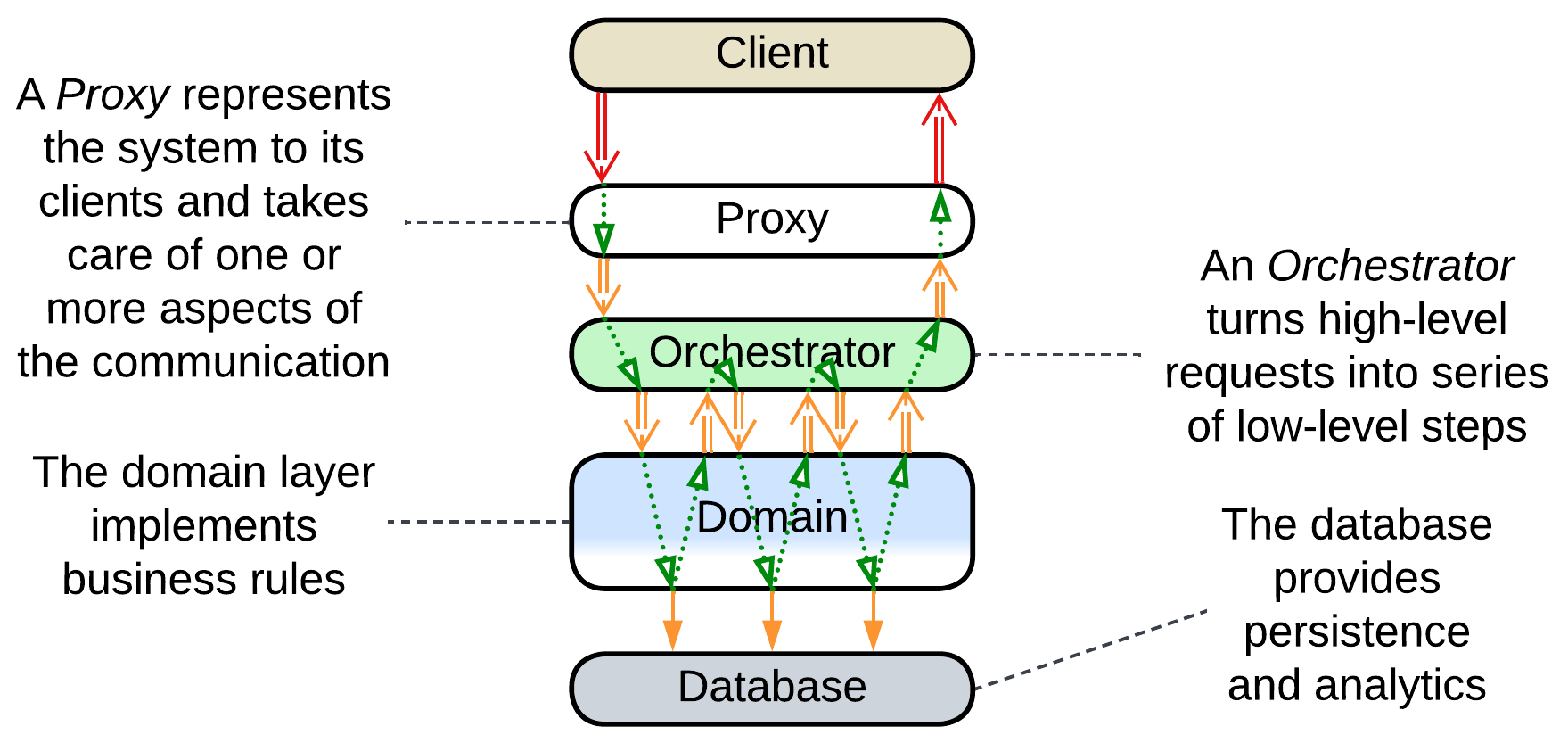
It is also common to:
- Have the business logic divided into two layers.
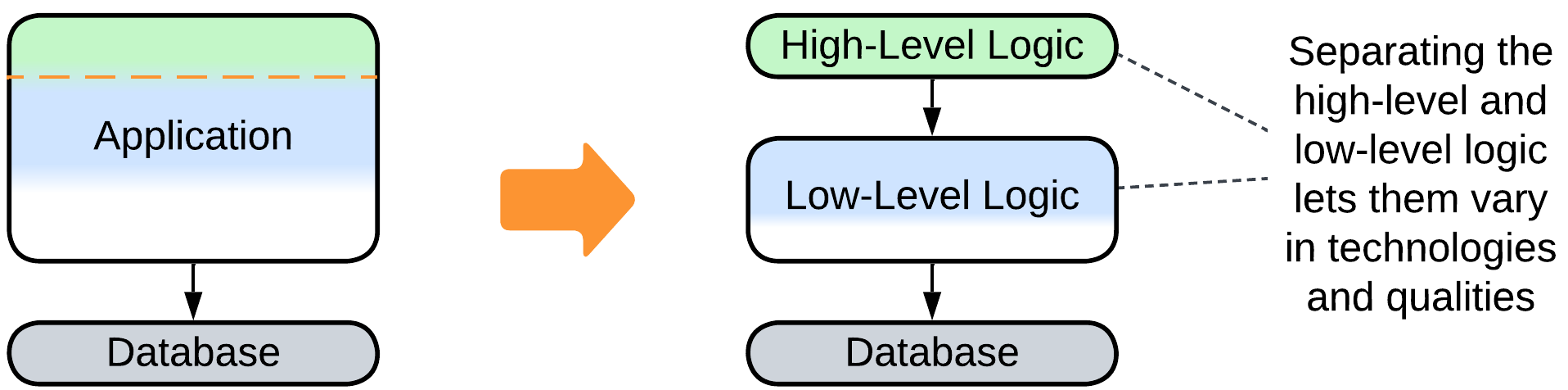
Evolutions that help large projects#
The main drawback (and benefit as well) of Layers is that much or all of the business logic is kept together in one or two components. That allows for easy debugging and fast development in the initial stages of the project but slows down and complicates work as the project grows in size [MP]. The only way for a growing project to survive and continue evolving at a reasonable speed is to divide its business logic into several smaller, thus less complex, components that match subdomains (bounded contexts [DDD]). There are several options for such a change, with their applicability depending on the domain:
- The middle layer with the main business logic can be divided into Services leaving the upper Orchestrator and lower database layers intact for future evolutions.
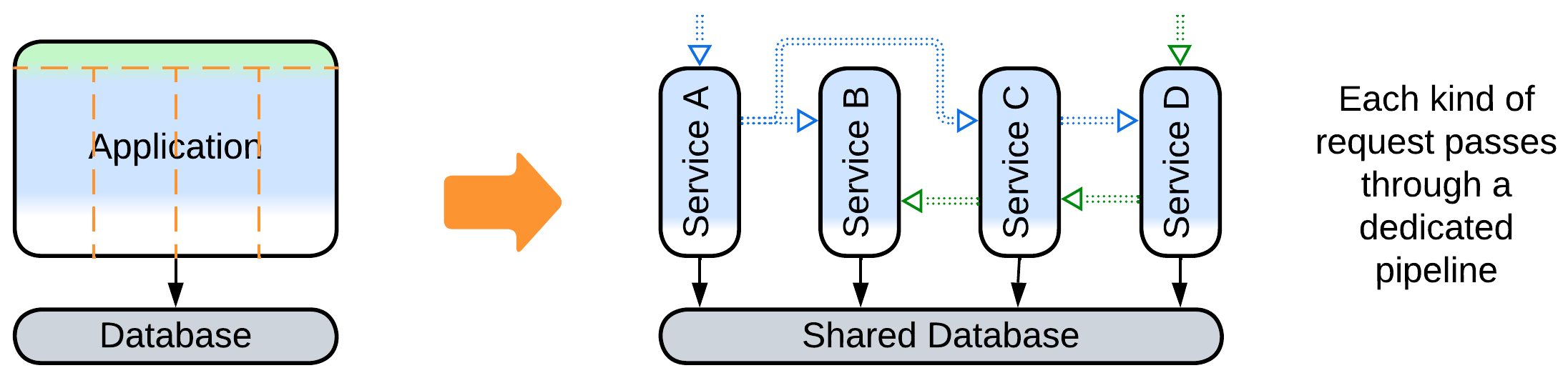
- Sometimes the business logic can be represented as a set of directed graphs which is known as Event-Driven Architecture.
- If you are lucky, your domain makes a Top-Down Hierarchy.
Evolutions that improve performance#
There are several ways to improve the performance of a layered system. One we have already discussed for Shards:
- Space-Based Architecture co-locates the database and business logic and scales both dynamically.
Others are new:
- Merging several layers improves latency by eliminating the communication overhead.
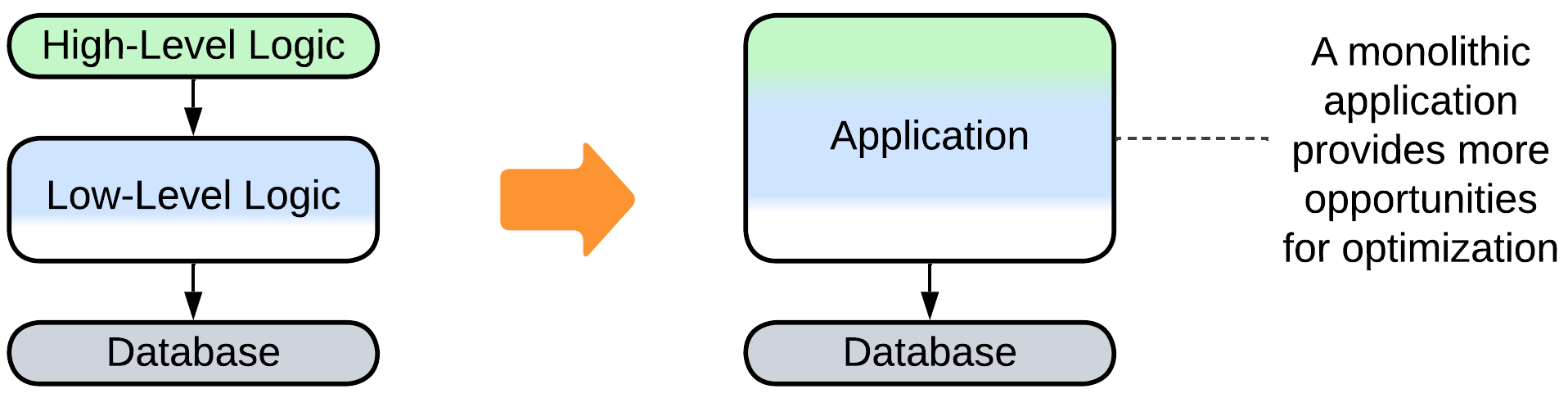
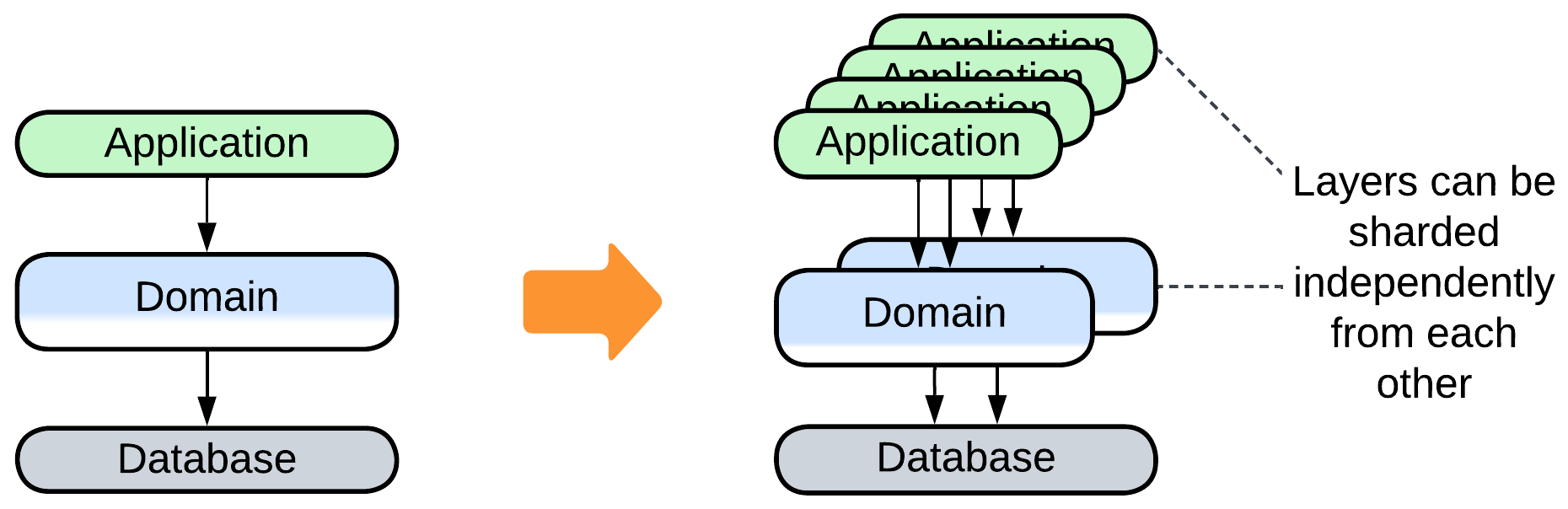
- Scaling some of the layers may improve throughput.
- Polyglot Persistence is the name for using multiple specialized databases.
Evolutions to gain flexibility#
The last group of evolutions to consider is about making the system more adaptable. We have already discussed the following evolutions for Monolith:
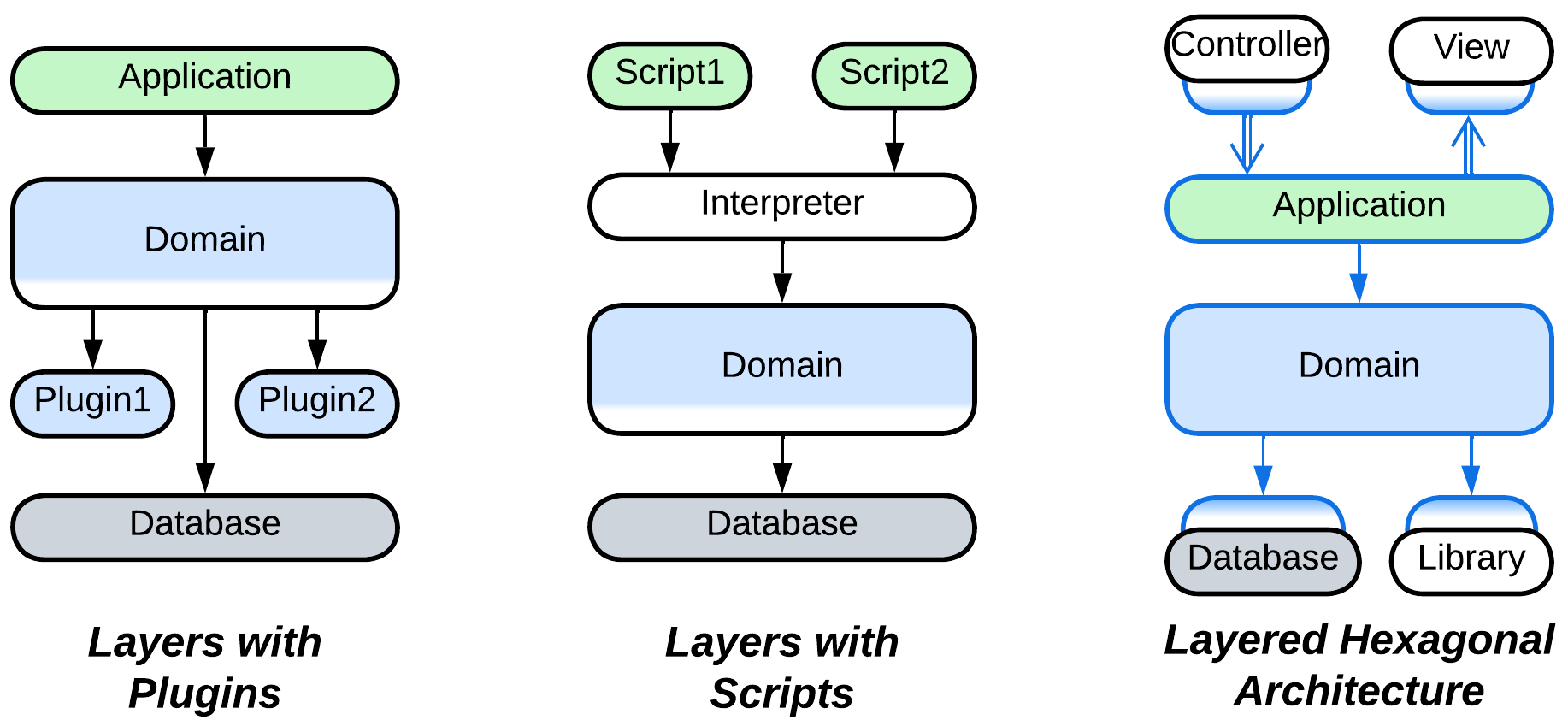
- The behavior of the system may be modified with Plugins.
- Hexagonal Architecture allows for abstracting the business logic from the technologies used in the project.
- Scripts allow for customization of the system’s logic on a per client basis.
There is one new evolution which modifies the upper (orchestration) layer:
- The orchestration layer may be split into Backends for Frontends to match the individual needs of several kinds of clients.
Summary#
Layered architecture separates the high-level logic from the low-level details. It is superior for medium-sized projects as it supports rapid development by two or three teams, is flexible enough to resolve conflicting forces, and provides many options for further evolution, which will come in handy when the project grows in size and complexity.